O problema
Havia um volume grande de itens publicados em marketplaces e portais de terceiros (onde a marca não controla o cadastro do anunciante) sem descrição adequada ou com texto insuficiente. Isso piora a clareza da oferta, reduz confiança e tende a prejudicar conversão em relação a anúncios bem descritos. Obter esse texto de forma manual não escala: muitas URLs, layouts diferentes por canal e atualização constante dos anúncios.
A solução
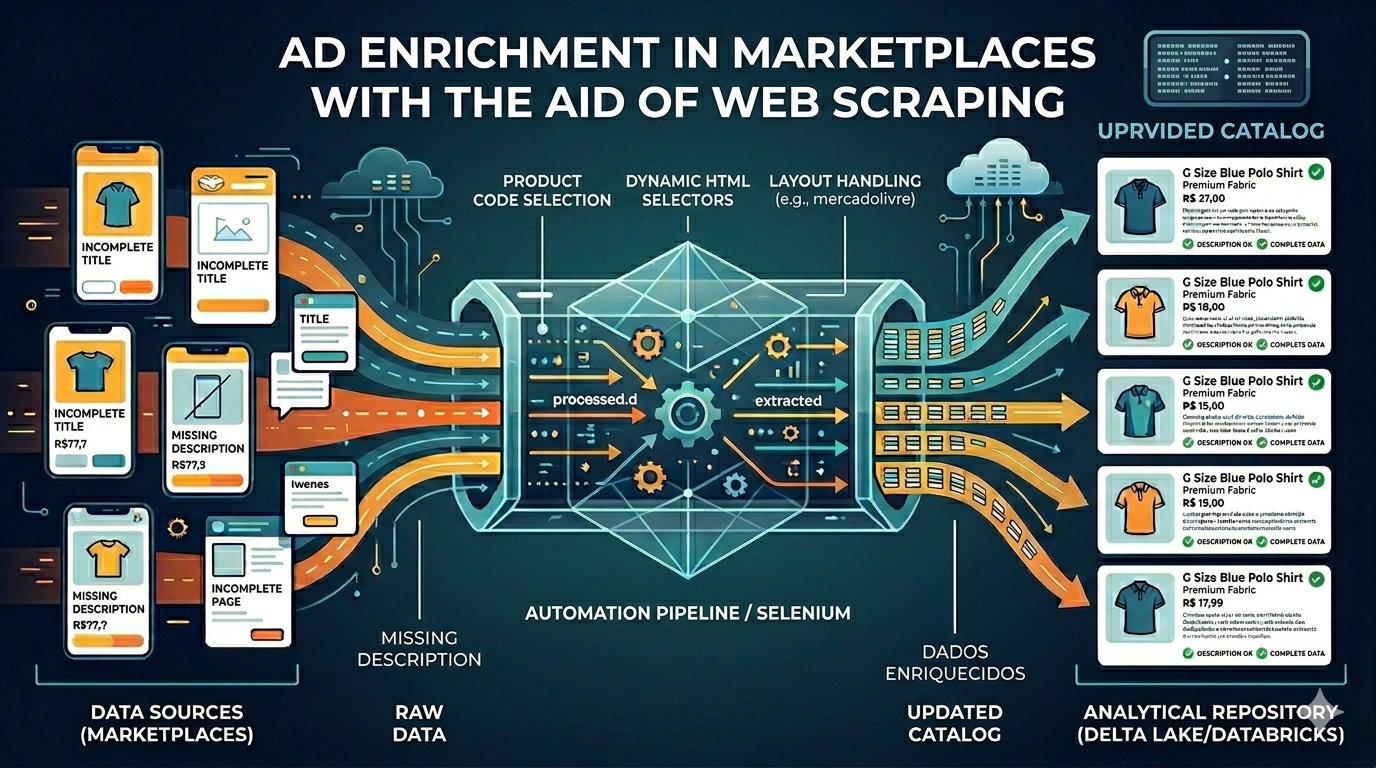
Foi desenvolvido um coletor automatizado baseado em automação de navegador (Selenium), orientado por códigos de produto. Para cada código, o fluxo:
- Consulta o canal (cada um com estrutura HTML própria).
- Extrai dados da listagem (título, valor exibido e link para a página do item).
- Abre a página de detalhe e lê o bloco de descrição com seletores específicos por site.
- Consolida tudo em um arquivo tabular e publica o resultado em ambiente de dados analítico (Databricks, tabela Delta), permitindo cruzar com a base interna de catálogo.
- A solução foi modularizada por quatro origens distintas, entre elas o Mercado Livre, tratando diferenças de layout, espera de carregamento e formatos de preço/texto.
Resultados
- Cadastro enriquecido: descrições obtidas a partir do que o terceiro já publicou, alinhadas ao anúncio real visto pelo cliente final.
- Menos esforço operacional: substituição de coleta manual repetitiva por execução programada em notebook.
- Base única para análise e reuso: dados versionados por execução (data de coleta) e integrados ao lakehouse para auditoria, comparação entre canais e eventual uso em correção de conteúdo ou campanhas.