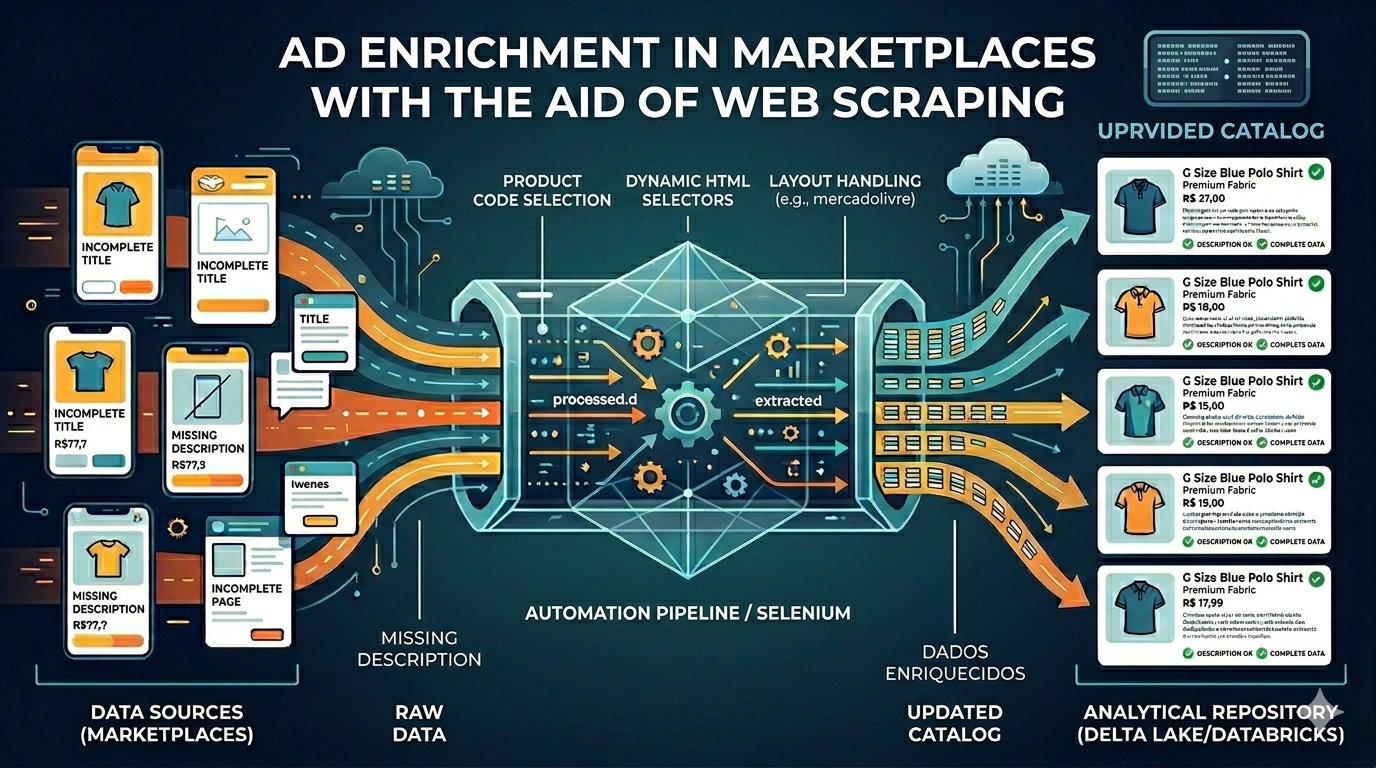
The problem
A large volume of items on third-party marketplaces and portals (where the brand does not control the seller listing) lacked adequate descriptions or had insufficient text. That hurts clarity, trust, and conversion versus well-described listings. Manual collection does not scale: many URLs, different layouts per channel, and constant listing updates.
The solution
An automated collector was built with browser automation (Selenium), driven by product codes. For each code, the flow:
- Visits the channel (each with its own HTML structure).
- Extracts listing data (title, displayed price, and item link).
- Opens the detail page and reads the description block with site-specific selectors.
- Consolidates results into a tabular file and publishes to the analytics environment (Databricks, Delta table), enabling joins with the internal catalog.
- The solution was modularized across four distinct sources—including Mercado Livre—handling layout differences, load waits, and price/text formats.
Results
- Enriched listings: descriptions sourced from what third parties already published, aligned to the listing the end customer sees.
- Less operational toil: scheduled notebook runs instead of repetitive manual collection.
- A single analytics base: data versioned by run date (collection date) and integrated into the lakehouse for auditing, cross-channel comparison, and downstream content or campaign workflows.