Introdução
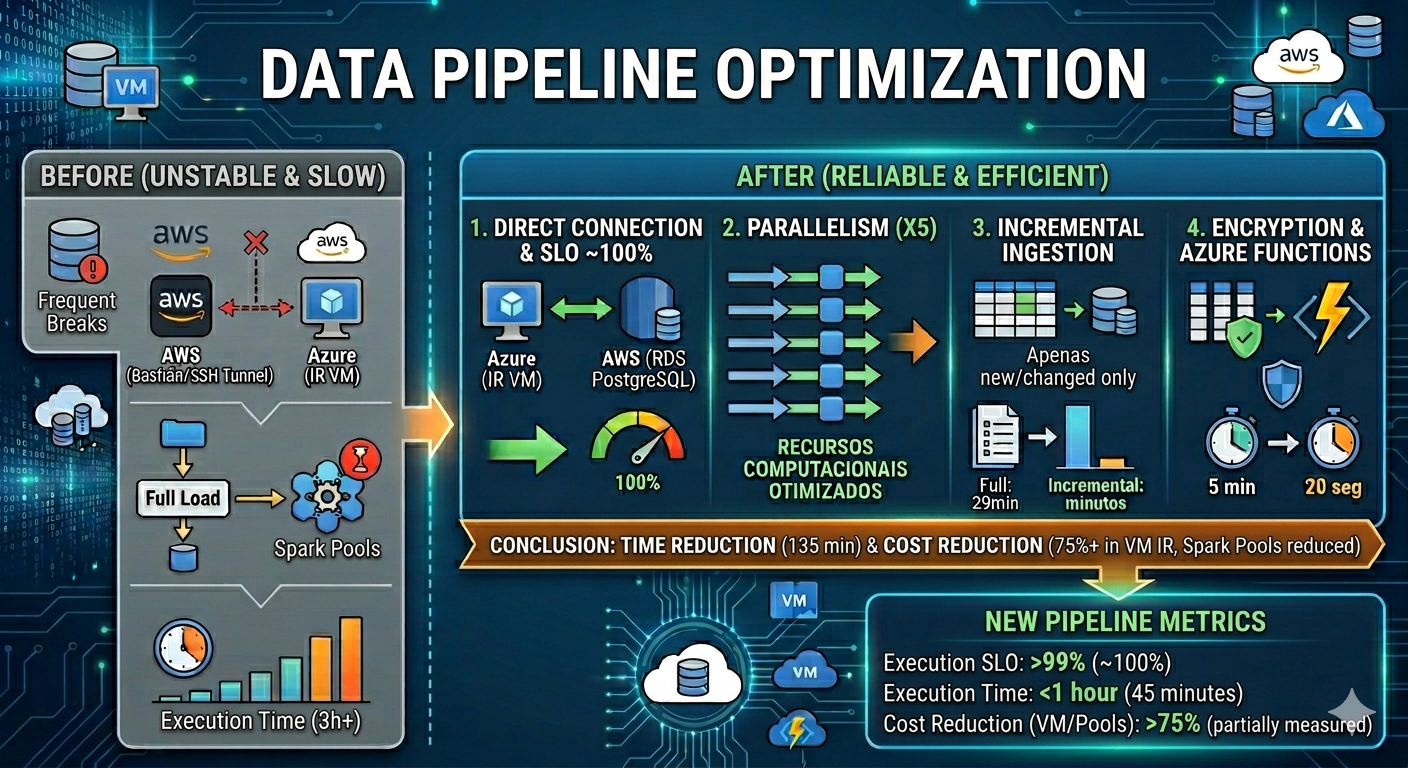
Os objetivos da otimização eram tornar o processamento de dados oriundos do banco de dados de produto confiável e com tempo de disponibilidade aceitável, com SLO de execução em 99% e tempo de disponibilidade dos dados em menos de 1 hora. A princípio, as execuções dessa pipeline costumavam quebrar frequentemente e eram executadas em torno de três horas.
Nesse documento explicamos as ações realizadas, os resultados obtidos e os impactos em termos de confiabilidade e financeira.
Substituição do modo de conexão com o banco de dados
Conexão configurada de acesso da VM do Integration Runtime (Azure) com o servidor de banco de dados (AWS) era instável. Dependia de uma máquina bastion na AWS e conexão via túnel SSH da VM da Azure para esse bastion na AWS. Hoje, fazemos uma conexão direta entre a VM do Integration Runtime com o banco PostgreSQL na AWS.
Após esse ajuste, não tivemos mais casos de perda de conexão com o banco de dados, fazendo o SLO de execução subir para perto de 100%.
Paralelismo
Antigamente, as tabelas eram ingeridas de forma sequencial. Após discussões com os times de SRE, DBRE e devs de produto, fizemos vários testes com diferentes parâmetros de paralelismo. O que mais se adequou ao nosso cenário foi o paralelismo de 5. Dessa forma, conseguimos fazer um bom uso dos recursos computacionais da nossa máquina que realiza o processamento, reduzindo o tempo de execução da pipeline.
Incremental
Apenas uma tabela estava com ingestão incremental. Após avaliação das demais tabelas e o tempo que as mesmas levavam para serem ingeridas como full load, vemos oportunidades de melhora para algumas delas.
As tabelas escolhidas para ingestão incremental resultaram numa diminuição de 29 minutos de processamento, no total. Abaixo está a economia de tempo para cada uma delas.
Modificação do método de criptografia de dados sensíveis
Antes, a criptografia era realizada através de uma Spark Pool, com código Python. A alternativa usada foi a criptografia por meio de uma Azure Function. O uso de functions nesse cenário reduz o tempo de processamento e de início de sessão que tínhamos com o Spark Pools, com notebooks, além de reduzir custos com isso, já que pools do Spark são caros. Uma criptografia que durava em torno de 5 minutos passou a durar 20 segundos com a Azure Function.
Conclusão
Após as otimizações descritas, a pipeline apresentou uma redução de tempo de 135 minutos e de custo, por parte do uso da VM do Integration Runtime, de 75%. Novos números de execução da pipeline:
| Parâmetro | Objetivo | Resultado |
|---|---|---|
SLO de execução | 99% | ~100% |
Tempo de execução | 1 hora | 45 minutos |
Redução de custos | Não estipulado | >75% |