Introduction
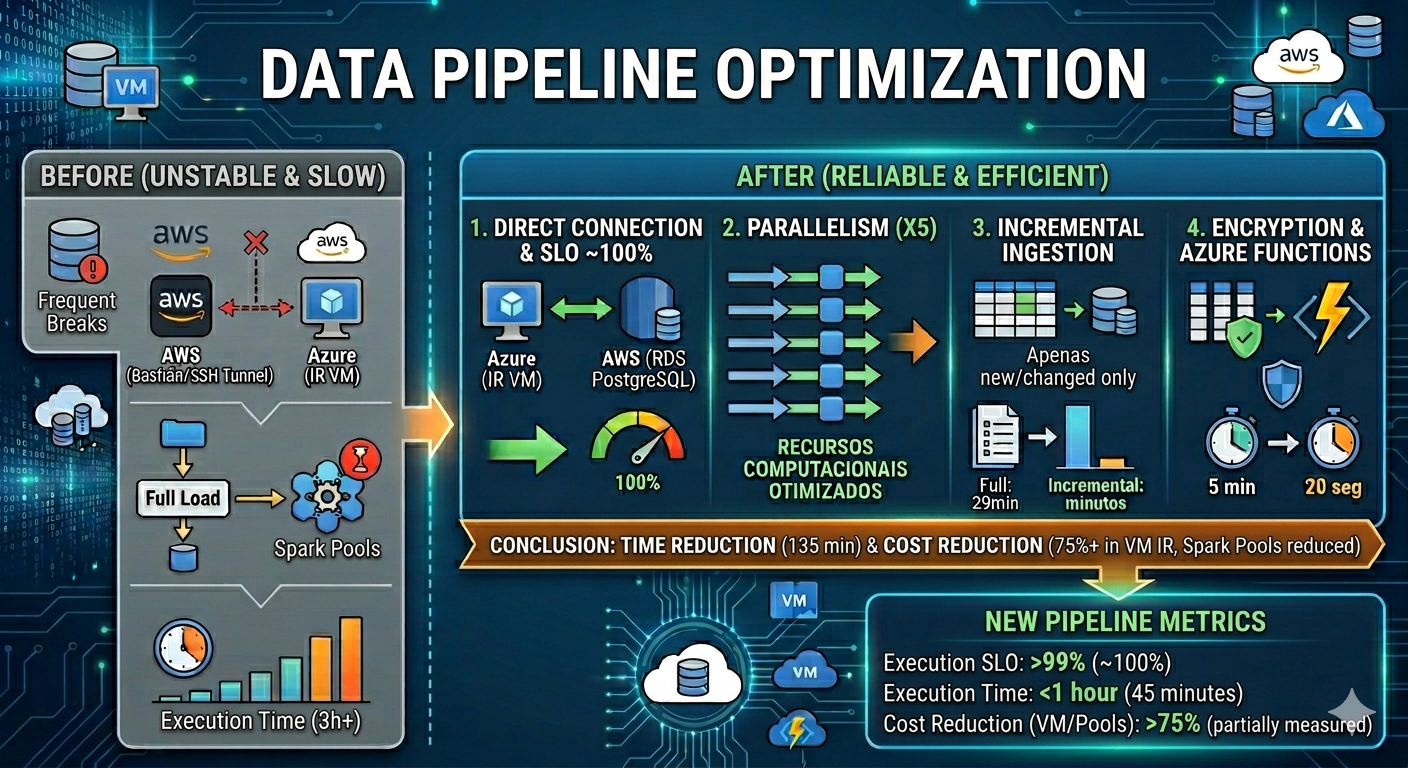
The goals were to make processing from the production database reliable with acceptable data freshness—an execution SLO around 99% and data available in under one hour. Initially, the pipeline failed often and took about three hours per run.
This write-up covers the changes, results, and impact on reliability and cost.
Database connectivity mode
Access from the Azure Integration Runtime VM to the database server (AWS) was unstable. It depended on an AWS bastion host and an SSH tunnel from the Azure VM to that bastion. We moved to a direct connection between the Integration Runtime VM and PostgreSQL on AWS.
After that change, we stopped seeing connection drops to the database, and the execution SLO moved close to 100%.
Parallelism
Tables used to be ingested sequentially. After working with SRE, DBRE, and product engineering, we tested different parallelism settings. Parallelism of 5 fit our scenario best, making better use of compute on the processing host and reducing runtime.
Incremental loads
Only one table used incremental ingestion. After reviewing the remaining tables and their full-load durations, we identified incremental opportunities.
The tables switched to incremental ingestion saved an estimated 29 minutes in total. Per-table savings:
Sensitive data encryption approach
Encryption previously ran in a Spark pool with Python. We moved encryption to an Azure Function. That reduced processing time and session startup overhead from Spark pools and notebooks, lowering cost—encryption that took ~5 minutes dropped to ~20 seconds with the function.
Conclusion
After these optimizations, pipeline runtime dropped by 135 minutes and Integration Runtime VM cost fell by about 75%. Updated targets versus results:
| Parameter | Target | Result |
|---|---|---|
Execution SLO | 99% | ~100% |
Runtime | 1 hour | 45 minutes |
Cost reduction | Not specified | >75% |