Visão geral
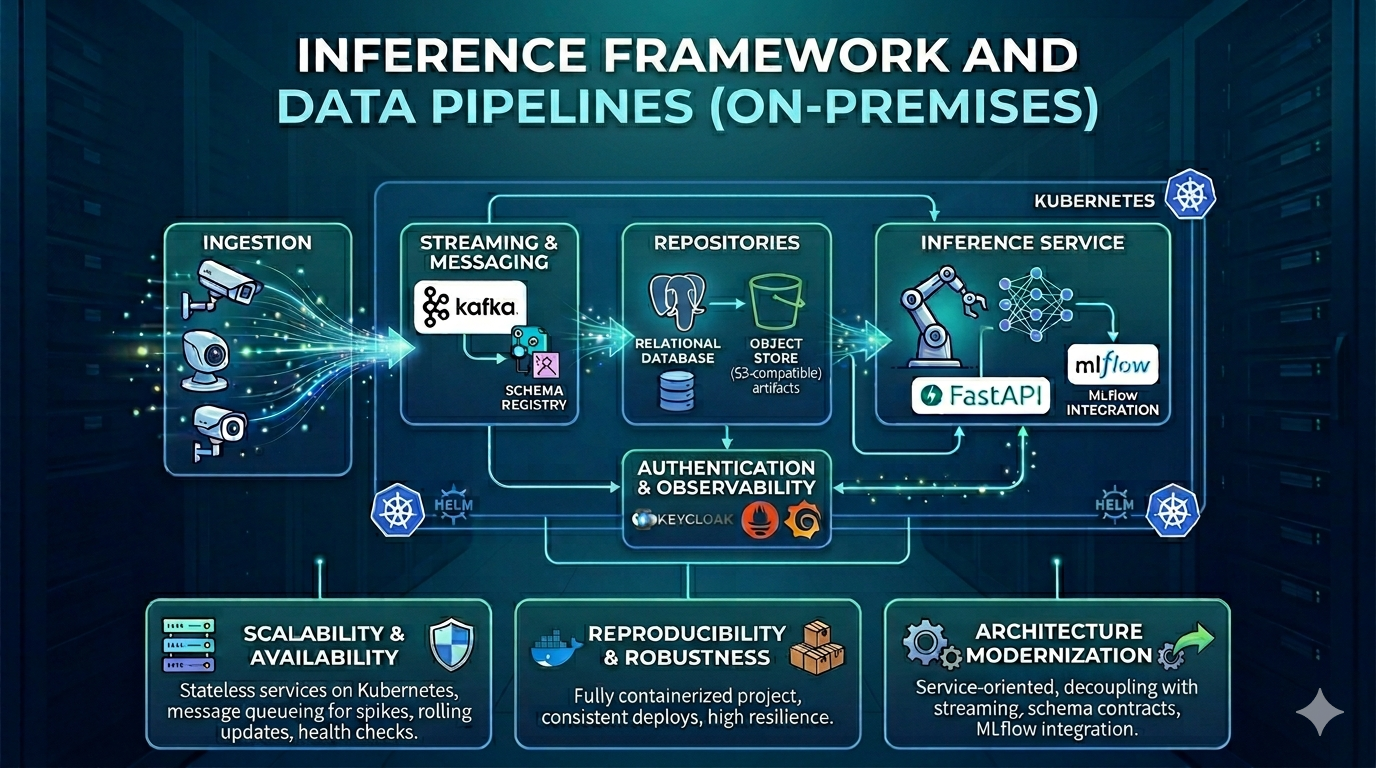
Arquitetura e o desenvolvimento de um pipeline de visão computacional on-premises, substituindo scripts monolíticos e gravação em disco local por streaming com contratos de esquema, object store, banco relacional e API de inferência integrada ao MLflow, implantada em Kubernetes. O novo modelo de detecção foi desenvolvido por um cientista de dados. Minha contribuição foi tornar esse modelo operável, observável e escalável em produção.
Problema
O fluxo anterior era um conjunto de scripts Python desorganizados, difícil de manter e sem separação clara de responsabilidades. Os dados eram gravados diretamente no sistema de arquivos da máquina onde o processamento rodava, o que limitava auditoria, backup e crescimento. Não havia streaming de eventos (fila de mensagens para desacoplar produtores e consumidores), nem object store, nem banco de dados relacional para metadados e resultados estruturados. Não havia empacotamento com Docker nem orquestração. Os deploys e dependências eram frágeis. Não havia ferramenta centralizada para versionamento e promoção de modelos. O modelo em uso era inferior ao novo modelo produzido pelo cientista de dados, mas o ambiente antigo não permitia operar esse modelo de forma confiável nem em escala.
Solução
Foi desenhada e implementada uma arquitetura orientada a serviços, com:
- Streaming: mensageria para ingestão e processamento assíncrono, com Schema Registry e contratos de dados versionados, reduzindo acoplamento entre componentes.
- Persistência: object store compatível com API S3 para artefatos e payloads grandes e banco PostgreSQL para metadados e consultas.
- Integração: conectores para mover dados entre o sistema de mensagens, o armazenamento e o banco, em vez de escrever tudo em disco local.
- Inferência e API: serviço HTTP (FastAPI) para inferência, integrado ao MLflow para registro, versionamento e promoção de modelos.
- Segurança e observabilidade: autenticação e autorização em camada de API para requisições em endpoints específicos, auxilado pelo Keycloak.
- Operação: imagens Docker e Helm para parâmetros de deploy. O ambiente roda em Kubernetes.
O código de aplicação foi reorganizado em módulos (API, domínio, integração com MLflow, persistência), separando o que é orquestração e plataforma da entrega do modelo pelo cientista de dados.
Resultados
| Dimensão | O que melhorou |
|---|---|
| Escalabilidade | Serviços stateless atrás do orquestrador, fila absorve picos, object store e DB escalam por camada. |
| Disponibilidade | Rolling updates, health checks, dependências declaradas, menos downtime por deploy, failover com o Kubernetes. |
| Reprodutibilidade | Projeto altamente reprodutível em outros ambientes por estar conteinerizado. |
| Robustez | Sistema muito mais robusto que o anterior com uma alta escalabilidade e disponibilidade. |