Overview
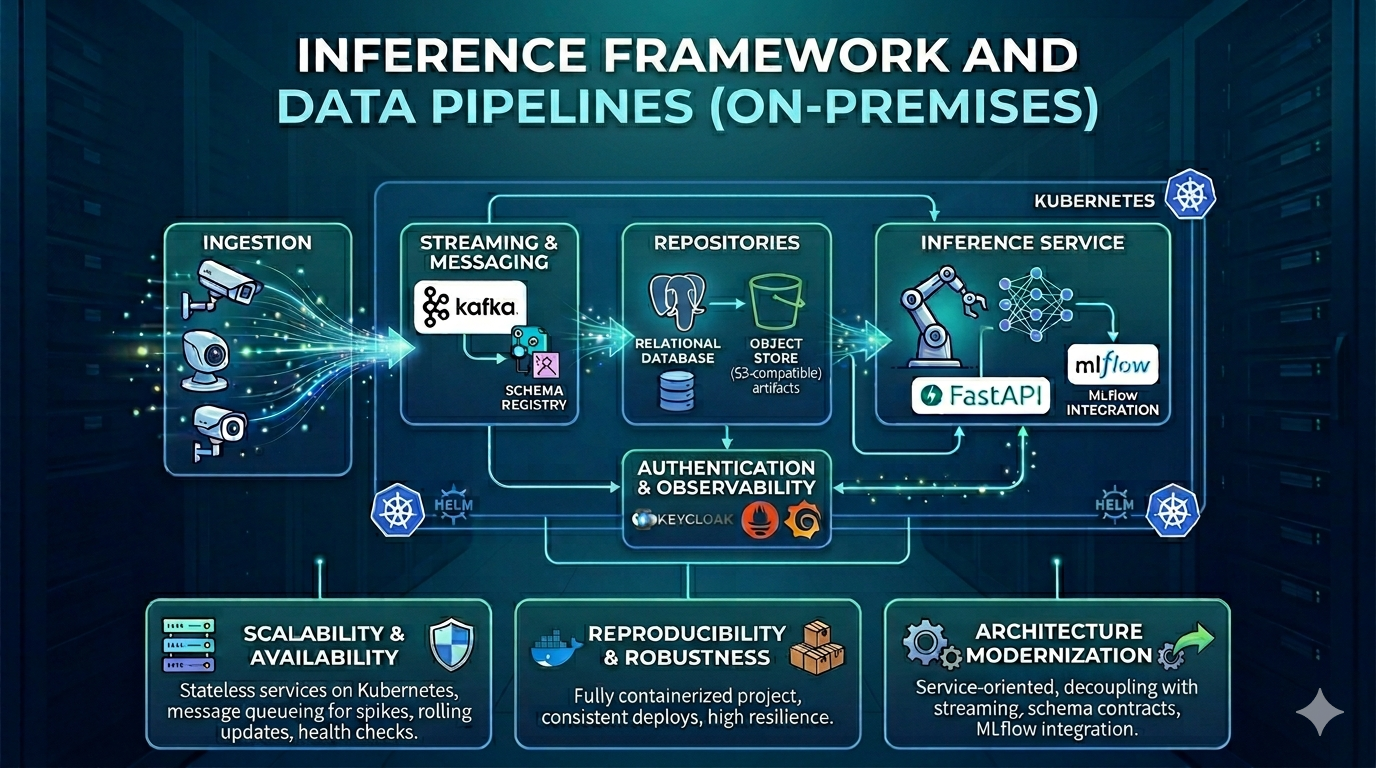
Architecture and delivery of an on-premises computer vision data pipeline, replacing monolithic scripts and local disk writes with streaming, schema contracts, object storage, a relational database, and an HTTP inference API integrated with MLflow, deployed on Kubernetes. A data scientist developed the new detection model; my contribution was making that model operable, observable, and scalable in production.
Problem
The previous flow was a set of disorganized Python scripts that were hard to maintain, with unclear separation of concerns. Data was written directly to the host filesystem, which limited auditing, backup, and growth. There was no event streaming (message queue to decouple producers and consumers), no object store, and no relational database for metadata and structured results. There was no Docker packaging or orchestration. Deployments and dependencies were fragile. There was no centralized tool for model versioning and promotion. The model in production lagged behind a newer model produced by the data scientist, but the legacy environment could not run that model reliably or at scale.
Solution
A service-oriented architecture was designed and implemented, including:
- Streaming: messaging for asynchronous ingestion and processing, with a schema registry and versioned data contracts to reduce coupling between components.
- Persistence: S3-compatible object storage for artifacts and large payloads, and PostgreSQL for metadata and queries.
- Integration: connectors to move data between messaging, storage, and the database instead of writing everything to local disk.
- Inference & API: an HTTP service (FastAPI) for inference, integrated with MLflow for registration, versioning, and model promotion.
- Security & observability: API-layer authentication and authorization for specific endpoints, supported by Keycloak.
- Operations: Docker images and Helm for deployment parameters. The environment runs on Kubernetes.
Application code was reorganized into modules (API, domain, MLflow integration, persistence), separating platform orchestration from model delivery owned by the data scientist.
Results
| Dimension | What improved |
|---|---|
| Scalability | Stateless services behind the orchestrator, the queue absorbs spikes, object storage and the DB scale by layer. |
| Availability | Rolling updates, health checks, declared dependencies, less downtime per deploy, Kubernetes-driven failover. |
| Reproducibility | Highly reproducible across environments thanks to containers. |
| Robustness | A much more robust system than before, with strong scalability and availability. |