Contexto do problema
O ambiente analítico tinha baixa padronização técnica, transformações eram desenvolvidas de forma manual, sem um padrão único de modelagem, sem validações automáticas e com pouca previsibilidade entre ambientes. Isso gerava:
- Dificuldade de escalar novos modelos dbt.
- Risco de inconsistência nos dados por ausência de contratos e testes.
- SQL sem padrões de código e difícil de manter.
- Diferenças de comportamento entre desenvolvimento, validação e produção.
- Retrabalho no processo de revisão e produtização.
Solução
Foi realizada uma estruturação completa do projeto com foco em engenharia de dados moderna, qualidade e governança, usando o dbt.
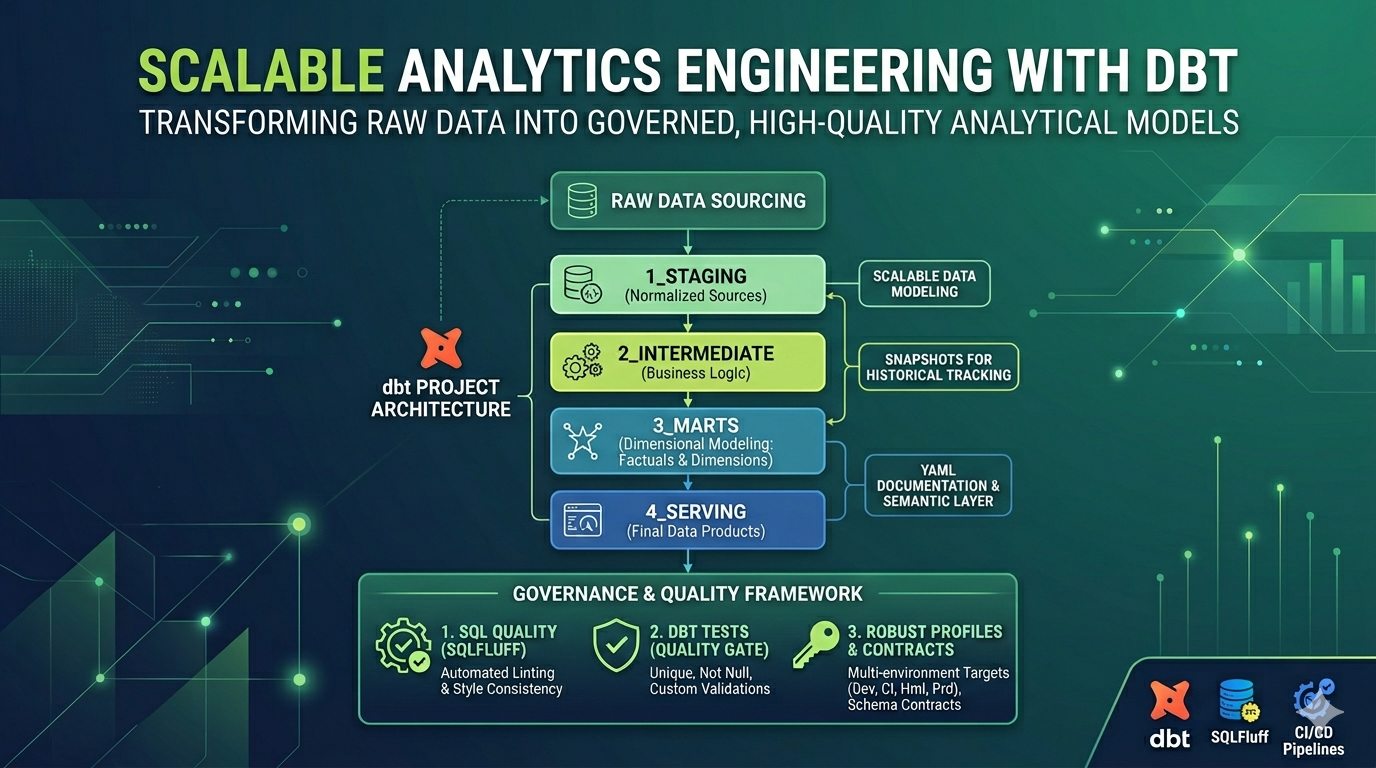
1) Arquitetura de projeto dbt por camadas
A modelagem foi organizada em uma estrutura clara e evolutiva:
- 1_staging: padronização das fontes e normalização inicial.
- 2_intermediate: regras de negócio reutilizáveis e consolidações.
- 3_marts: modelagem dimensional (fatos e dimensões) para consumo analítico.
- 4_serving: tabelas finais para produtos de dados e consumo downstream.
Essa separação ajuda na legibilidade, reuso e isolamento de responsabilidades.
2) Modelagem de dados com foco em qualidade semântica
A modelagem foi implementada com princípios de Data Warehouse e Analytics Engineering:
- Uso de natural keys e surrogate keys conforme o papel da entidade.
- Definição explícita de granularidade por modelo.
- Construção de fatos e dimensões com chaves de integração consistentes.
- Snapshots para preservar histórico de mudanças em entidades sensíveis.
- Documentação funcional e técnica em YAML para modelos e colunas.
3) Boas práticas de dbt e governança de projeto
O projeto foi padronizado com práticas que sustentam escala:
- Organização de schemas por domínio.
- Tags para segmentação e execução seletiva.
- Materializations adequadas por camada.
- Controle de mudança de schema (on_schema_change) para reduzir quebra silenciosa.
- Contracts ativados em camadas críticas para garantir consistência de interface de dados.
- Uso de pacotes do ecossistema dbt para produtividade e qualidade.
4) Qualidade de código SQL com SQLFluff
Foi implementado um linting com SQLFluff, com regras de estilo e estrutura para manter consistência de código:
- Padronização de formatação SQL.
- Redução de ambiguidades de escrita.
- Melhoria da legibilidade de queries complexas.
Resultado: menos divergência de estilo, menor custo de manutenção e revisão mais objetiva.
5) Testes dbt como gate de confiabilidade
Foram estruturadas validações em múltiplos níveis com testes dbt:
- not_null para colunas críticas.
- unique para unicidade de chaves.
- accepted_values para domínios controlados.
- Testes em modelos dimensionais e fatos para proteger regras de negócio.
Com isso, qualidade deixou de ser manual e passou a ser parte nativa da esteira técnica.
6) Profiles robusto para múltiplos ambientes
O arquivo profiles.yml foi estruturado para suportar fluxo multiambiente com isolamento e segurança:
- Targets dedicados para dev, ci, hml e prd.
- Separação de credenciais por ambiente.
- Padrão consistente de configuração de catálogo/schema.
- Autenticação apropriada para execução local e pipelines.
- Previsibilidade do comportamento do dbt entre todos os estágios.
Esse desenho eliminou “funciona no meu ambiente” e aumentou a confiabilidade de promoção entre ambientes.
Resultados
✅ Padronização técnica real: arquitetura, nomenclatura e práticas passaram a ser uniformes.
✅ Mais confiança em produção: linting + testes + contracts reduziram risco de incidentes.
✅ Maior qualidade de modelagem: modelos mais claros, auditáveis e fáceis de evoluir.
✅ Adoção positiva pelo time: analytics engineers passaram a reportar feedbacks consistentemente positivos sobre o novo fluxo.
✅ Manutenção menos custosa.