Problem context
The analytics environment had weak technical standardization: transformations were built manually, with no single modeling standard, no automatic validation, and limited predictability across environments. That led to:
- Difficulty scaling new dbt models.
- Risk of inconsistency from missing data contracts and tests.
- Unstandardized SQL that was hard to maintain.
- Inconsistent behavior across dev, validation, and production.
- Rework in review and productionization.
Solution
The project was fully structured around modern data engineering, quality, and governance using dbt.
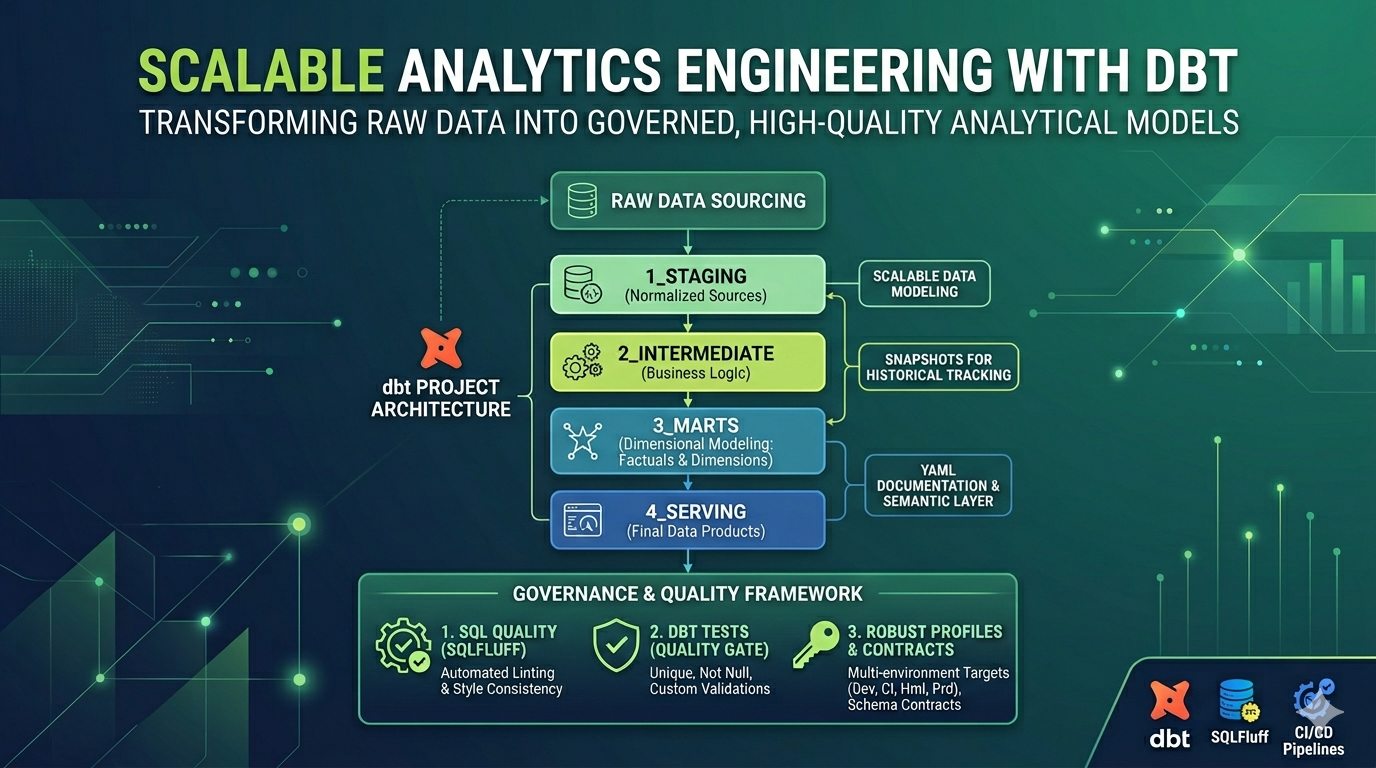
1) Layered dbt project architecture
Modeling was organized in a clear, evolvable structure:
- 1_staging: source standardization and initial normalization.
- 2_intermediate: reusable business rules and consolidations.
- 3_marts: dimensional modeling (facts and dimensions) for analytics.
- 4_serving: final tables for data products and downstream consumers.
This separation improves readability, reuse, and separation of concerns.
2) Data modeling focused on semantic quality
Modeling followed data warehouse and analytics engineering principles:
- Natural keys and surrogate keys used according to the entity’s role.
- Explicit grain per model.
- Facts and dimensions with consistent join keys.
- Snapshots to preserve change history for sensitive entities.
- Functional and technical documentation in YAML for models and columns.
3) dbt best practices and project governance
The project was standardized with practices that support scale:
- Schemas organized by domain.
- Tags for segmentation and selective runs.
- Appropriate materializations by layer.
on_schema_changeto reduce silent breakage.- Contracts on critical layers to guarantee interface consistency.
- Ecosystem dbt packages for productivity and quality.
4) SQL code quality with SQLFluff
Linting with SQLFluff was introduced with style and structure rules to keep code consistent:
- Consistent SQL formatting.
- Less ambiguity in how queries are written.
- Better readability of complex queries.
Outcome: less style drift, lower maintenance cost, and more focused code review.
5) dbt tests as a reliability gate
Validations were structured at multiple levels with dbt tests:
- not_null on critical columns.
- unique for key uniqueness.
- accepted_values for controlled domains.
- Tests on dimensional models and facts to protect business rules.
Quality moved from a manual check to a native part of the technical pipeline.
6) Robust profiles for multiple environments
profiles.yml was structured to support a multi-environment flow with isolation and security:
- Dedicated targets for dev, CI, staging, and prod.
- Environment-specific credentials.
- Consistent catalog/schema configuration.
- Authentication suited to local runs and pipelines.
- Predictable dbt behavior at every stage.
This design removed “works on my machine” issues and made promotion between environments more reliable.
Outcomes
✅ Real technical standardization: architecture, naming, and practices became uniform.
✅ More confidence in production: linting + tests + contracts reduced incident risk.
✅ Higher modeling quality: clearer, more auditable models that are easier to evolve.
✅ Strong team adoption: analytics engineers reported consistently positive feedback on the new workflow.
✅ Lower maintenance overhead.