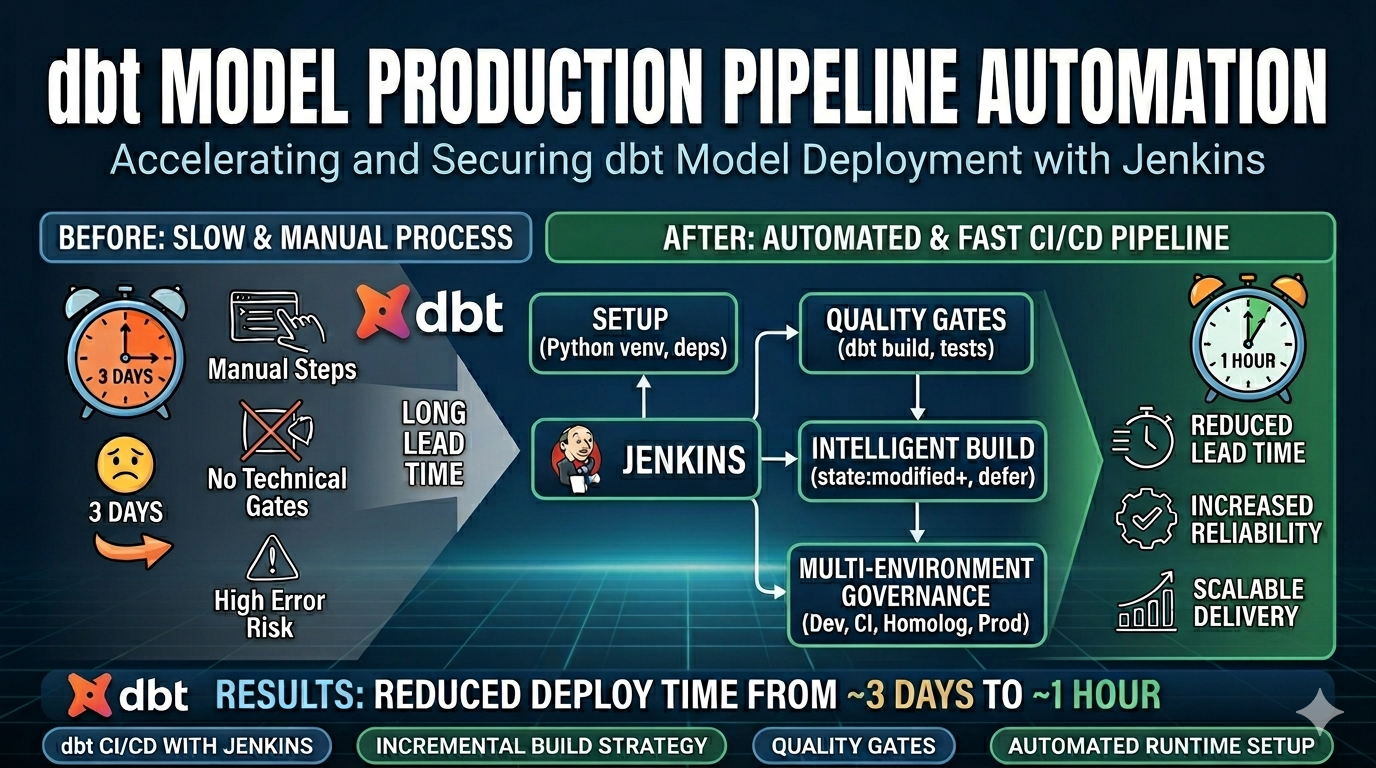
O problema
A produtização de novos modelos analíticos era lenta, manual e pouco confiável. O fluxo dependia de execução operacional (com forte intervenção humana), sem gates técnicos padronizados para validar qualidade antes da promoção entre ambientes. Isso causava:
- Lead time elevado para colocar novos modelos em produção.
- Alto risco de erro por falta de validações automatizadas.
- Baixa previsibilidade no processo de deploy.
- Dificuldade de escalar o volume de entregas do time.
Historicamente, a publicação de novas tabelas levava em torno de 3 dias.
A solução
Foi estruturada e implementada uma esteira de CI/CD para dbt com foco em produtização rápida, segura e auditável, usando Jenkins e scripts de automação do projeto.
1) Desenho da esteira por tipo de execução
Foram estruturadas pipelines específicas para diferentes contextos de entrega (ex.: validação de PR, fluxo de merge e execução por ambiente).
- Roteamento de execução conforme branch/evento.
- Separação de responsabilidade entre validação e promoção.
- Padronização do fluxo para todos os modelos novos.
2) Gate de qualidade na produtização
A esteira foi configurada para não promover código sem validação técnica:
- Execução de dbt build como validação.
- Suporte a testes e validações declarativas já definidos no projeto.
- Reprovação automática quando há falhas de build/qualidade.
- Rastreabilidade do que foi validado em cada execução.
- Linting do código com SQLFluff.
3) Otimização de tempo e custo computacional com o uso do state do dbt nas validações
Foi implementada execução incremental orientada a mudança para acelerar as pipelines de validação:
- Uso de estratégia com state:modified+ quando existe estado anterior.
- Fallback para build completo quando necessário.
- Redução de tempo de CI sem perder segurança de impacto.
Resultados
✅ Redução drástica de lead time: produtização de novas tabelas caiu de ~3 dias para cerca de 1 hora.
✅ Maior confiabilidade operacional: deploy deixou de depender de execução manual e passou a seguir gates automatizados.
✅ Escalabilidade do time: aumento da capacidade de entrega de novos modelos com menor risco.
✅ Padronização de processo: fluxo único de validação e promoção.
✅ Satisfação do time técnico: analytics engineers passaram a reportar feedbacks consistentemente positivos sobre a nova esteira.