Overview
This project automated collecting, analyzing, and recording stability-test failures, reducing manual toil and improving operational efficiency.
The problem
During large-scale stability testing, failures surfaced on dashboards. Recording them was fully manual and spanned multiple steps:
- Continuous dashboard review to spot failures.
- Manual checks for existing records in issue trackers.
- Creating new records or updating existing ones.
- Adding details such as occurrence counts, affected devices, and logs.
Challenges included:
⚠️ High time cost for operators.
⚠️ Human error risk.
⚠️ Repetitive work that did not scale.
⚠️ Slower response to failures.
⚠️ Less focus on higher-value engineering work.
The solution
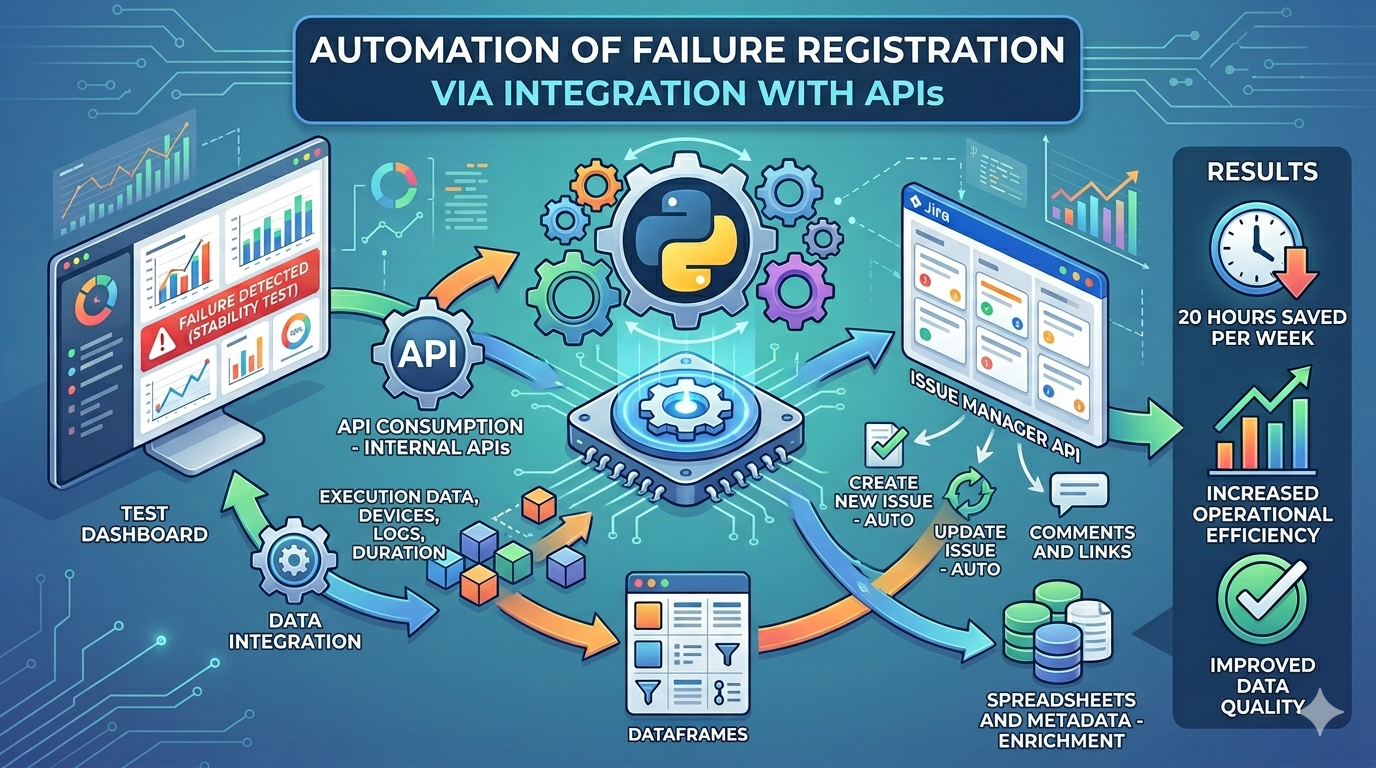
An automated Python solution integrated systems via APIs across the failure lifecycle:
-
Automated data collection
- Consumed dashboard data via internal APIs.
- Extracted relevant failure details (runs, devices, logs, etc.).
-
Processing and analysis
- Structured data in DataFrames.
- Filters and grouping to highlight meaningful events.
-
Issue tracker integration (API)
- Automatic checks for related existing records.
- Updates to existing records with new occurrences.
- Cloning similar records from other projects when needed.
-
Decision automation
- Automatic actions: create, update, or flag manual follow-up.
- Rich comments with details and useful links.
-
Spreadsheets and metadata
- Auxiliary data to enrich records.
- Standardized fields in the tracker.
-
Logging and traceability
- Execution logs for monitoring and debugging.
Results
✅ Roughly 20 hours per week of manual work removed
✅ Higher operational efficiency in failure recording
✅ Faster detection and response
✅ Better quality, consistency, and standardization of recorded data
✅ Fewer human errors in analysis and recording
✅ More capacity for analytical and strategic work